See everything.
Set MetricsPort in your config. /metrics comes up automatically. The repo includes a docker-compose.yml that runs Postgres, Redis, Prometheus, and Grafana together. One command, full observability stack.
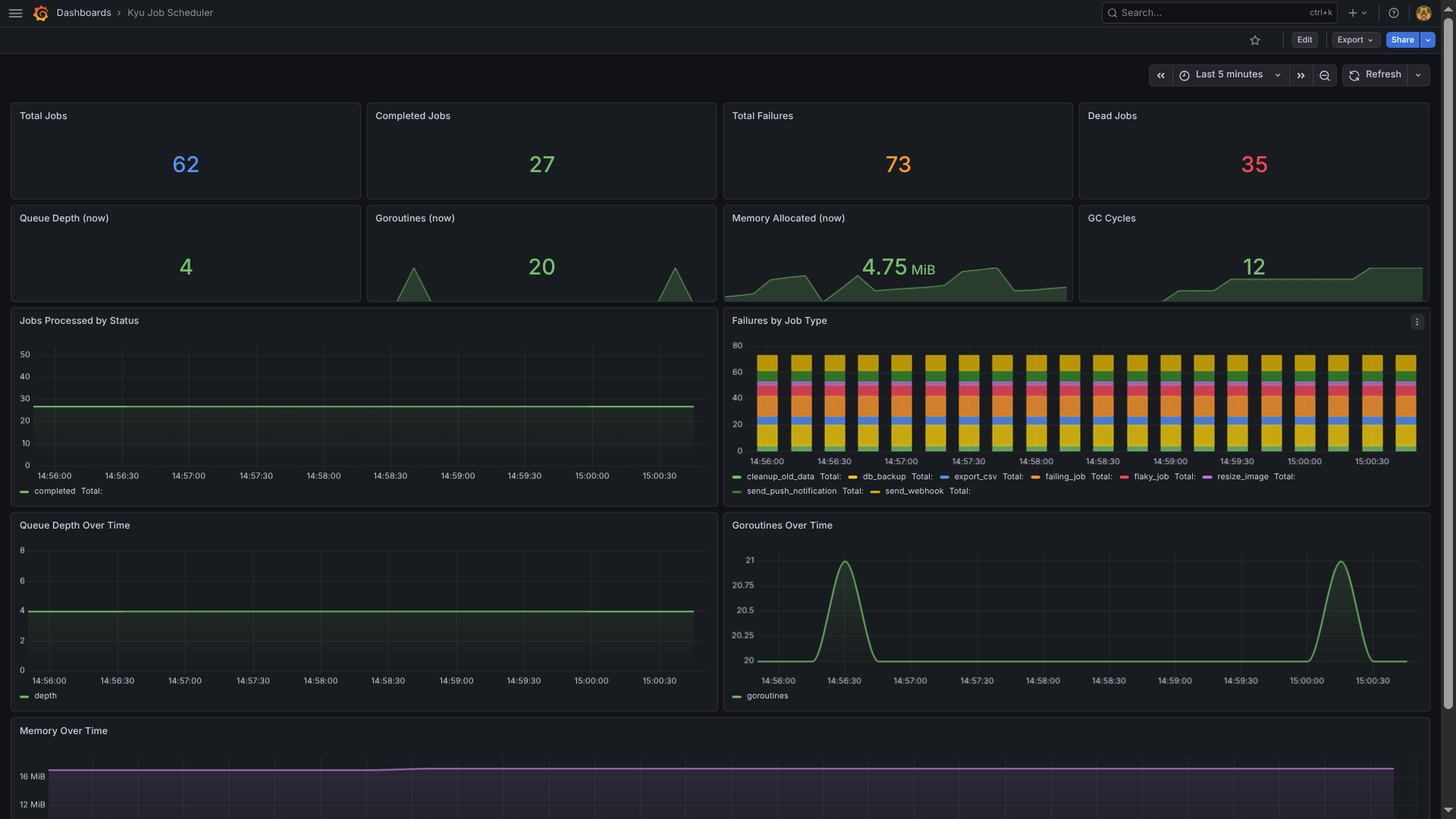
[dashboard]
Grafana dashboard — queue depth, throughput, failure rates by job type
github.com/codetesla51/kyu
| Metric | Type | Description |
|---|---|---|
| kyu_jobs_total | counter | Total jobs ever submitted |
| kyu_jobs_processed_total | counter_vec | Completed jobs, labelled by status |
| kyu_job_failures_total | counter_vec | Failures, labelled by job_type |
| kyu_jobs_dead_total | counter | Jobs that exhausted all retries |
| kyu_queue_depth | gauge | Jobs currently waiting in Redis |